วัตถุประสงค์
1. แสดงรูปแบบจำลองของโปรแกรมตัวแปลภาษา เพื่อใช้ประกอบการศึกษาและวางพื้นฐานการออกแบบ
2. สร้างความเข้าใจ เพื่อให้เห็นคุณค่าของการใช้ภาษาคอมพิวเตอร์ และความยากง่ายในการใช้ภาษาอย่างมีประสิทธิภาพ
ดังนั้นจึงแบ่งเนื้อหาออกเป็นดังนี้
Part I แนะนำหลักการทั่วไปและแบบจำลองของโปรแกรมตัวแปลภาษา
Part II แสดงตัวอย่างการออกแบบและการทำงานของโปรแกรมตัวแปลภาษา
Part III การจัดการโครงสร้างข้อมูล, Recursion, Storage Allocation, Block Structure, Conditions และ Pointers ที่นำมาประยุกต์ใช้ในการทำงานกับรูปแบบจำลองตัวแปลภาษา
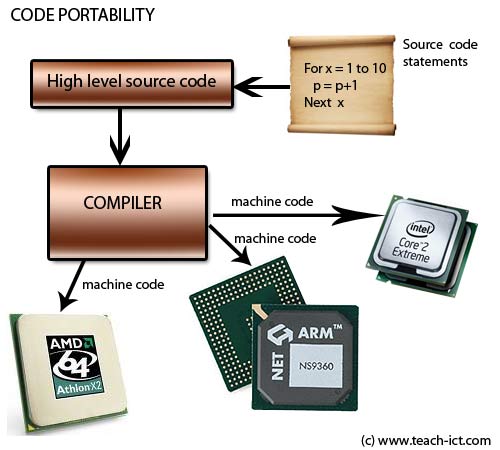
Computer Languages
Structure of Computer Languages
1. Character Set
• Alphabetic Symbols
• Special Characters
2. Data Types
• Constants or Literals
• Numeric
Fixed-point or Integer such as Positive, Zero, Negative
Floating-point or Real such as Single or Double Precision
Complex
• Character String such as bits or bytes string manipulation
• Logical
• Others Data Types
3. Data Structures
• Arrays, Stacks
• File Structures such as organizing in Sequential, Random, Inverted Files
• Pointers
• Procedures and Functions
4. Naming and any Rules
5. Operators and Internal Functions
• Arithmetic Operators such as +, -, *, /, DIV, MOD, ^
• Logical Operators such as NOT, AND, OR, XOR
• String Operators such as concatenate, search, extract, replace of string
6. Structure of Statement Lines and Program
7. Statements or Commands or Instructions
• Declarative Statements
• Assignment Statements
• Control Statements
• Conditional Statements
• I/O Statements
• Debugging or Compiler-directive Statements
• Others
Part I
PL/I Program
WCM: PPROCEDURE (RATE,START,FINISH);
DECLARE (COST,RATE,START,FINISH) FIXED BINARY(31) STATIC;
COST = RATE * (START – FINISH) + 2 * RATE * (START – FINISH – 100);
RETURN (COST);
END;
ตัวแปลภาษาจะต้องทำอย่างไรกับโปรแกรม WCM นี้ เพื่อให้ได้มาซึ่งโปรแกรมคำสั่งภาษาเครื่อง
1. แยกแยะ กระจาย String ให้ได้ Basic Elements (or Tokens)
WCM -------- Label
PROCEDURE -------- Keyword
COST -------- Variable or Identifier
= -------- Operator
2. ตรวจสอบ จดจำรูปแบบประโยคคำสั่ง (Syntactic Construction) เพื่อหาความหมายของการสั่งงาน (Semantic)
คำสั่งแรก เป็นคำสั่ง PROCEDURE พร้อมค่า Arguments สามตัว
คำสั่งที่สอง เป็นคำสั่งอธิบายตัวแปรพร้อมคุณสมบัติที่จะใช้งาน
คำสั่งที่สาม เป็นการกำหนดค่านิพจน์เลขคณิตแก่ตัวแปร COST
คำสั่งที่สี่ เป็นการส่งค่าตัวแปรกลับไปยังโปรแกรมที่เรียกใช้
คำสั่งที่ห้า แสดงการจบชุดของคำสั่งนี้
3. กำหนดพื้นที่และตำแหน่งของหน่วยความจำให้แก่ค่าคงที่ ตัวแปรต่างๆ
4. จัดสร้างชุดคำสั่งภาษาเครื่องที่เหมาะสมถูกต้อง
1. Recognizing Basic Element
Lexical Analysis parsing the source program into the proper syntaxtic classes (Scan)
วิเคราะห์คำ โดยการแยกแยะ String ออกเป็นคำ ๆ (Tokens or Basic Elements) โดยอาศัยตัว Separators ซึ่งได้แก่ ช่องว่าง (Blank or Spaces) โอเปอเรเตอร์ (Operators) สัญลักษณ์พิเศษที่ใช้คั่นวรรคตอน (Punctuation Symbols or Special Symbol) เพื่อแยกประเภทของ Elements ดังกล่าว
• Identifiers
• Literals
• Terminal Symbols เช่น Operators, Keywords, แล้วจัดสร้างเป็น Uniform Symbols (Token ที่มีขนาดไม่คงที่จัดการลำบาก จึงสร้าง Uniform Systems ซึ่งมีขนาดคงที่)
Lexical Analysis : หมายถึง 1 Token
Uniform Symbol = is the same size
2. Recognizing Syntactic Units and Interpreting Meaning
Basic Syntactic Constructs (Token)
WCM : PROCEDURE ( RATE , START , FINISH ) ;
Valid Statement
DECLARE ( COST , RATE , START , FINISH ) FIXED BINARY ( 31 ) STATIC ;
Valid Statement
COST = RATE * ( START - FINISH ) + 2 * RATE * ( START - FINISH -
100 ) ;
Valid Statement
RETURN ( COST ) ;
Valid Statement
END ;
Valid Statement
หน้าที่
- ตรวจสอบ จดจำ วลีคำสั่ง Syntactic Constructs Syntactic Phrase
- แปลความหมายในการสั่งทำงาน (Interpret the Meaning)
วิธีการ
Semantic - Intermediate Form
Reduction Rules
Action Routines
(ใช้กฎ Reductions เพื่อกำหนดรูปแบบประโยคคำสั่ง ว่าประกอบขึ้นมาด้วย ดครงสร้างพื้นฐานอะไรบ้าง แล้วควรจะเรียกใช้รูทีนส่วนไหน (Action Routines) ของตัวแปลภาษามาทำงานในการตีความหมายต่อไป)
Intermediate Forms
ประโยชน์
ช่วยในการ Optimization และยังทำให้การ Optimization แบ่งการทำงานของตัวแปลภาษาออกเป็นการทำงาน 2 ส่วน คือ Machine-Independent (Lexical Analysis, Syntax Analysis, Interpretation)
กับ Machine-dependent (Storage Allocation, Code Generation, Assembly)
การสร้าง Intermediate Forms ขึ้นอยู่กับโครงสร้างของ Syntactic Constructs สามรถแบ่งได้เป็น 3 ชนิด
- Arithmetic Statements
- Non-arithmetic Statements
- Non-Executable Statements
Arithmetic Statements
COST = RATE * ( START - FINISH ) + 2 * RATE * ( START - FINISH -
100 ) ;
1. Parse Tree เป็นการนำ Binary Tree มาประยุกต์ใช้กับ Binary Operator ( +, -, *, /, **)
โดยให้ Root Node เป็น Operator
Left-son Node เป็น Operand ตัวแรก
Right-son Node เป็น Operand ตัวที่สอง
2. Matrix
สำหรับ Arithmetic Statements
Index Operator Operand-1 Operand-2
M1 - START FINISH
M2 * RATE M1
M3 * 2 RATE
M4 - START FINISH
M5 - M4 100
M6 * M3 M5
M7 + M2 M6
M8 = COST M7
สำหรับ Non-Arithmetic Statements
Source Statement : RETURN (COST);
END;
จะได้ Matrix ดังนี้
Index Operator Operand-1 Operand-2
M1 RETURN COST
M2 END
คำสั่งอื่นๆ เช่น คำสั่ง DO, IF, GO TO เป็นต้น
สำหรับ Non-Executable Statements
No Intermediate Form but have some table of information about Identifiers
เช่น คำสั่ง DECLARE ของภาษา PL/I
คำสั่ง DIMENSION ของภาษา FORTRAN, BASIC
Storage Assignment
หน้าที่
Code Generation
Matrix Line. Matrix Entry Generated Codes
L 1,START
1. - START FINISH S 1,FINISH
ST 1,M1
L 1,RATE
2. * RATE M1 M 0,M1
ST 1,M2
L 1,=F’2’
3. * 2 RATE M 0,RATE
ST 1,M3
L 1,START
4. - START FINISH S 1,FINISH
ST 1,M4
L 1,M4
5. - M4 100 S 1,=F’100’
ST 1,M5
L 1,M3
6. * M3 M5 M 0,M5
ST 1,M6
L 1,M2
7. + M2 M6 A 1,M6
ST 1,M7
L 1,M7
8. = COST M7 ST 1,COST
(Length = 92 Bytes)
Optimization (Machine-independent)
จากตัวอย่างของ Matrix โปรแกรมชุดคำสั่งของ WCM ปรากฎว่ามีนิพจน์ย่อย 2 ตัวที่ซ้ำกันคือนิพจน์ย่อย START - FINISH เนื่องจากนิพจน์ดังกล่าวให้ผลลัพธ์ในการทำงานเหมือนกัน ดังนั้นจึงสามารถตัดออกจาก Matrix ได้ แล้วปรับปรุงการอ้างอิงแทนกันให้ถูกต้องต่อไป เรียกวิธีการจัดการแบบนี้ว่า Eliminate of Common Subexpression
Matrix with common subexp. Matrix after eliminate of common subexp.
1. - START FINISH 1. - START FINISH
2. * RATE M1 2. * RATE M1
3. * 2 RATE 3. * 2 RATE
4. - START FINISH 4.
5. - M4 100 5. - M1 100
6. * M3 M5 6. * M3 M5
7. * M2 M6 7. * M2 M6
8. = COST M7 8. = COST M7
วิธีอื่นๆ ได้แก่
- Compile Time Computation of Operations both of whose operands are constants.
- Movement of computations involving nonvarying operands out of loops.
- Use of the properties of Boolean expressions to minimize their computation. Etc.
นิยมแยกออกเป็นอีกขั้นตอนการทำงานหนึ่งก่อนที่จะนำ Matrix ไปดำเนินการในขั้น Code Generation ต่อไป
Optimization (Machine-dependent)
พิจารณาจากตัวอย่าง
1. สามารถลดการใช้ Temporary Storage สำหรับจัดเก็บค่าผลลัพธ์ของการคำนวณรายการใน Matrix ได้ โดยการไม่พยายามที่จะจัดเก็บผลการคำนวณไว้ในหน่วยความจำ (Store)
(คำสั่ง L และ ST เดิมใช้ถึง 14 คำสั่ง เมื่อทำการ Optimize แล้ว จะเหลือเพียง 5
คำสั่งเท่านั้น)
2. สามารถใช้คำสั่งที่สั้นลง แต่ทำงานได้รวดเร็วขึ้นกว่าเดิมอีก
(เช่น แทนที่จะใช้คำสั่ง M ก็ใช้คำสั่ง MR แทนได้)
นอกจากจะลดพื้นที่ขนาดโปรแกรมแล้ว ยังช่วยลดเวลาการ execute ลงไปอีกด้วยถึงเกือบสองเท่า
ปกติการ Optimization มักจะทำควบคู่ไปพร้อมกับการทำ Code Generation นอกจากนั้นแล้วยังน่าที่จะนำเอาเทคนิคของ Conditional Macro Pseudo-ops มาประยุกต์ผสมใช้ด้วย จะช่วยทำให้การสร้าง Code มีความยืดหยุ่น มีประสิทธิภาพมากยิ่งขึ้นอีก
Assembly Phase
ค่าคงที่ (Literals) และตัวแปรตำแหน่ง (Symbolic Address) สำหรับผู้อ่านโปรแกรมอาจจะดูเหมือนง่าย แต่สำหรับตัวแปลภาษาแล้วจะต้องสร้างคำสั่งภาษาเครื่องที่ถูกต้องเสมอ
ตัวแปลภาษาสามารถที่จะใช้วิธีการสร้างค่าคงที่ และ ตัวแปรต่างๆ โดยใช้วิธีการอ้างอิงไปยังตำแหน่งที่จัดเก็บค่าคงที่ และ ตัวแปรดังกล่าวในช่วงของการทำ Storage Allocation ได้ แต่อย่างไรก็ตาม ตัวแปลภาษาก็ไม่สามารถที่จะกำหนดค่าที่แท้จริงของ Labels ได้ จนกว่าจะมีการสร้าง Code ทั้งหมกเสร็จเรียบร้อยเสียก่อน
ดังนั้นจริงๆ แล้วการทำงานในขั้น Code Generation จึงต้องทำหน้าที่ 2 อย่าง
1. Generating Code
2. Defining Labels and resolving all references
เมื่อข้อ 1. คือการทำ Code Generation Phase ที่เราได้กล่าวผ่านมาแล้ว ส่วนข้อ 2. จึงเป็นหน้าที่ของ Assembly Phase ซึ่งในทางปฎิบัติจริงๆ แล้วก็คือ Pass 2 ของ Assembler นั่นเอง
สรุปการทำงาน Part I ของตัวแปลภาษา
ลักษณะงานและปัญหา (Statement of Problem)
1. การแยกประเภทของข้อความ คำสั่งต่างๆ
(Recognizing Basic Elements)
Lexical Analysis Terminal Table
2. ตรวจสอบความถูกต้องของคำสั่งและความหมาย
(Recognizing Syntactic Unit and Interpreting Meaning)
Syntax Analysis Reductions
Semantic Action Routines
3. รูปแบบตัวกลาง (Intermediate Forms)
Parse Tree
Matrix
4. กำหนดการจัดเก็บ (Storage Allocation)
Storage Assignment Static, Dynamic Allocation
5. การสร้างรหัสภาษาเครื่อง (Code Generation)
Code Generation Code Production Table
Optimization
• Machine-Independent
• Machine-Dependent
รูปแบบทั่วไปของตัวแปลภาษา (General Model of Compilers)
1. Lexical Analysis
recognition of basic elements and creation of Uniform Symbols
2. Syntax Analysis
recognition of basic constructs through Reductions
3. Interpretation
definition of exact meaning, creation of Matrix and tables by Action Routines
4. Machine Independent Optimization
creation of more optimal Matrix
ขั้นที่ 1 - 4 เป็นช่วงของ Machine-independent Phase
5. Storage Assignment
modification of Identifier and Literal Tables. It makes entries in the Matrix that allow Code Generation to create code that allocates dynamic storage, and that also allow the Assembly phase to reserve the proper amounts of STATIC storage
6. Code Generation
use of macro processor to produce more optimal assembly codes
7. Assembly and Output
resolving symbolic addresses (labels) and generating machine language
ขั้นที่ 5 - 7 เป็นช่วงของ Machine-dependent Phase
เป้าหมายที่ 1. Object Code 2. Amount of Cores 3. Time to Execute
ซึ่งทั้งสามประการนี้มักจะก่อให้เกิดข้อขัดแย้งกันอยู่บ้างในตัวกว่าจะได้มา
สรุป โครงสร้างข้อมูลที่ใช้งานกับตัวแปลภาษา
A. Source Code
B. Uniform symbol Table
created by Lexical Analysis (List of Tokens) used for Syntax Analysis and Interpretation
C. Terminal Table
permanent table-list of all keywords and special symbols (pointed to by Uniform Symbols)
D. Identifier Table
all variables and temporary storage with information creation by Lexical Analysis
modified by Interpretation and Storage Allocation
referenced by Code Generation and Assembly
E. Literal Table similar to D.
F. Reductions
permanent table of decision rules in form of patterns for matching with the Uniform Symbols Table to discover syntactic structure
G. Matrix
intermediate form which created by Action Routines, optimized and then
used for Code Generation
H. Code Production
permanent table of definition, one entry defining code for each possible matrix operator
I. Assembly Code
created by Code Generation input to assembly phase (assembler)
J. Relocatable Object Code
final output of assembly phase ready to be used as input to Loader





0 comments:
Post a Comment